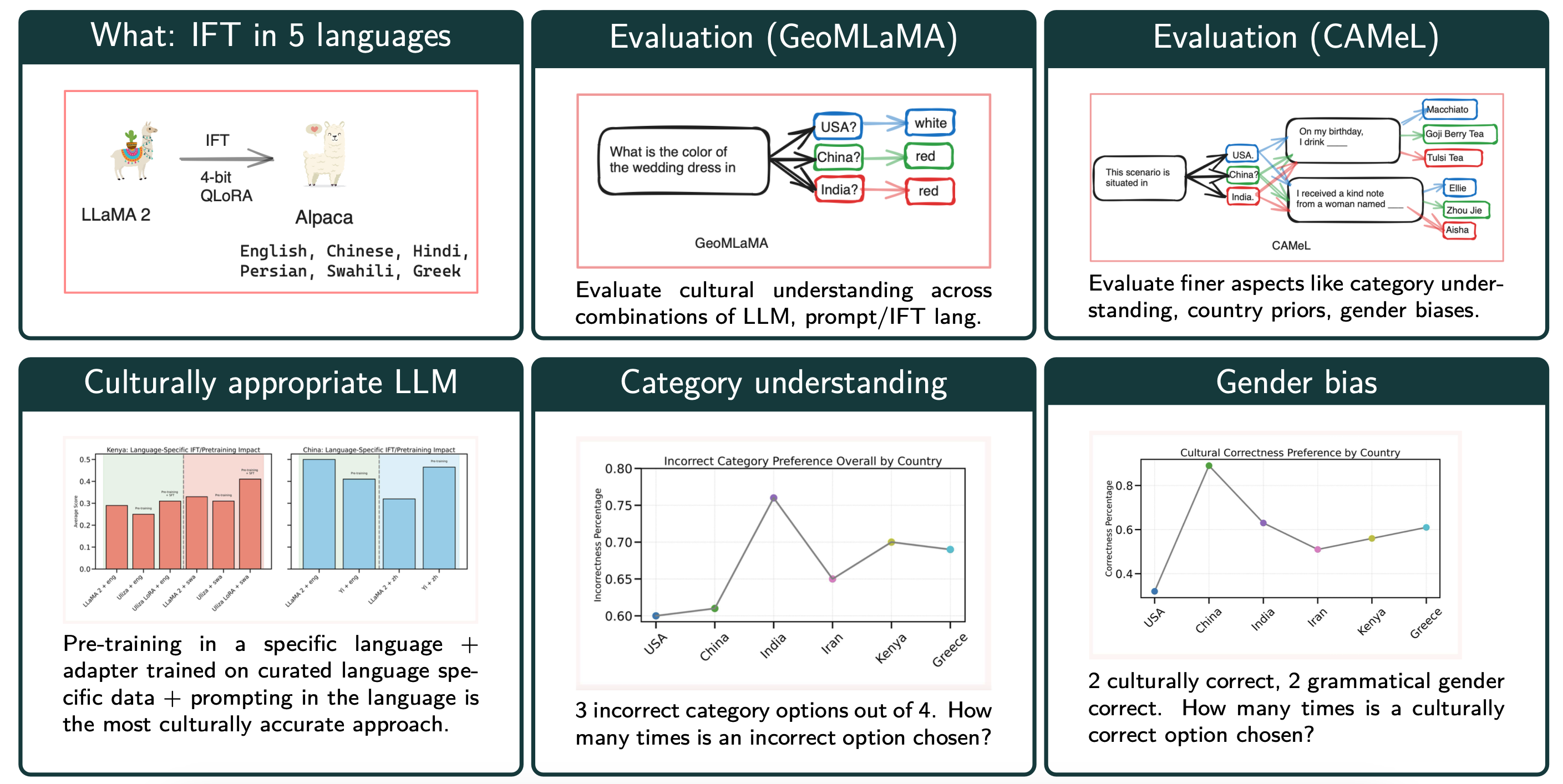
Exploring the intersection of language and culture in Large Language Models (LLMs), this study critically examines their capability to encapsulate cultural nuances across diverse linguistic landscapes. Central to our investigation are three research questions: the efficacy of language-specific instruction tuning, the impact of pretraining on dominant language data, and the identification of optimal approaches to elicit accurate cultural knowledge from LLMs. Utilizing the GeoMLaMA benchmark for multilingual commonsense knowledge and an adapted CAMeL dataset (English-only) for evaluation of nuanced cultural aspects, our experiments span six different languages and cultural contexts, revealing the extent of LLMs' cultural awareness. Our findings highlight a nuanced landscape: while language-specific tuning and bilingual pretraining enhance cultural understanding in certain contexts, they also uncover inconsistencies and biases, particularly in non-Western cultures. This work expands our understanding of LLMs' cultural competence and emphasizes the importance of integrating diverse cultural perspectives in their development, aiming for a more globally representative and equitable approach in language modeling.
If you find our work useful, please cite it!
@inproceedings{mukherjee-etal-2024-global,
title = "Global Gallery: The Fine Art of Painting Culture Portraits through Multilingual Instruction Tuning",
author = "Mukherjee, Anjishnu and
Caliskan, Aylin and
Zhu, Ziwei and
Anastasopoulos, Antonios",
editor = "Duh, Kevin and
Gomez, Helena and
Bethard, Steven",
booktitle = "Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
month = jun,
year = "2024",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.naacl-long.355",
pages = "6398--6415",
abstract = "Exploring the intersection of language and culture in Large Language Models (LLMs), this study critically examines their capability to encapsulate cultural nuances across diverse linguistic landscapes. Central to our investigation are three research questions: the efficacy of language-specific instruction tuning, the impact of pretraining on dominant language data, and the identification of optimal approaches to elicit accurate cultural knowledge from LLMs. Utilizing the GeoMLaMA benchmark for multilingual commonsense knowledge and an adapted CAMeL dataset (English-only) for evaluation of nuanced cultural aspects, our experiments span six different languages and cultural contexts, revealing the extent of LLMs{'} cultural awareness. Our findings highlight a nuanced landscape: while language-specific tuning and bilingual pretraining enhance cultural understanding in certain contexts, they also uncover inconsistencies and biases, particularly in non-Western cultures. This work expands our understanding of LLMs{'} cultural competence and emphasizes the importance of integrating diverse cultural perspectives in their development, aiming for a more globally representative and equitable approach in language modeling.",
}
